


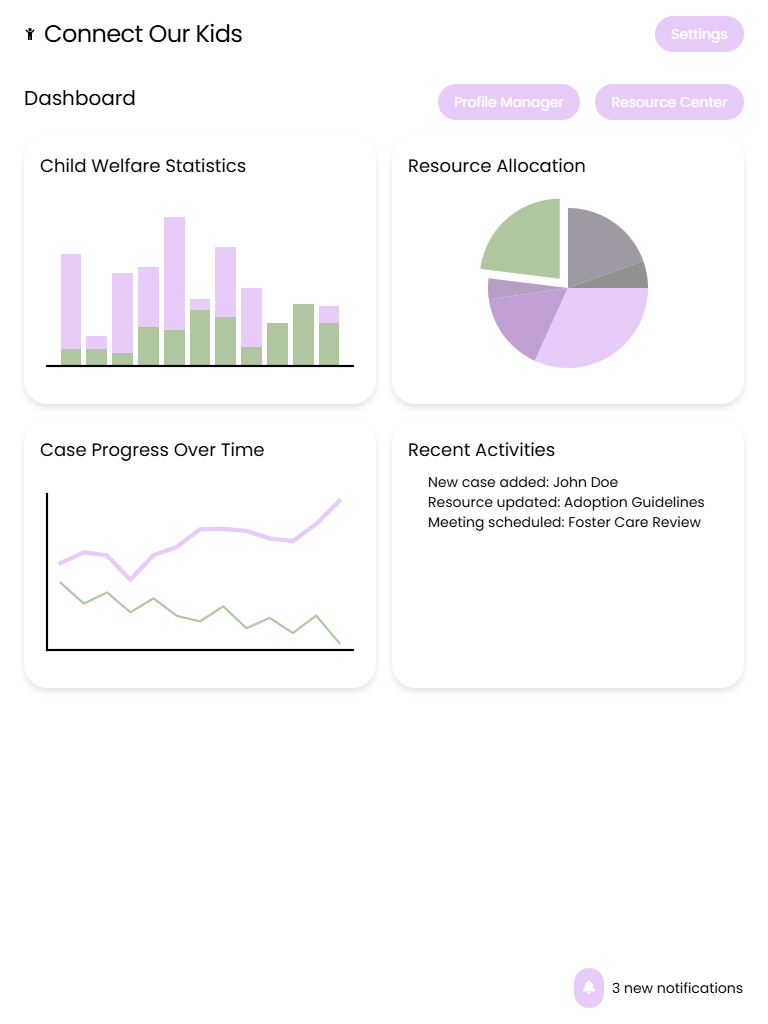
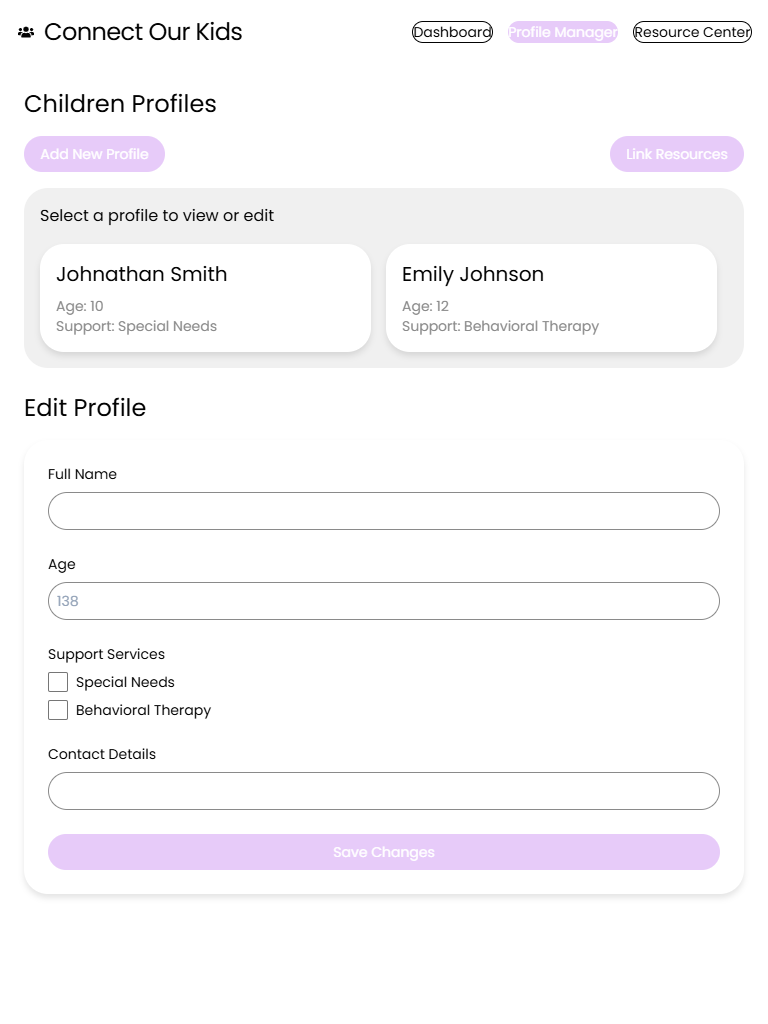

Project Kickoff 🚀
- Conducted initial strategy meetings with the Connect Our Kids team.
- Defined core objectives: UI/UX redesign, performance optimization, cross-browser compatibility.
- Created a high-level roadmap and development timeline.

Architecture & UI/UX Design Begins 💻
- Designed the system architecture using Angular 8+.
- Developed wireframes and prototypes based on existing user feedback.
- Planned API integrations with Apollo GraphQL for seamless backend connectivity.

Core Development Begins 🛠️
- Implemented a responsive and interactive UI using Angular framework.
- Integrated front-end components with Apollo GraphQL.
- Developed authentication and user role management system.

Performance Optimization Phase ⚡
- Implemented lazy loading and code splitting for improved efficiency.
- Optimized API calls and database queries for faster response times.
- Conducted security enhancements to mitigate XSS and CSRF vulnerabilities.

Cross-Browser Compatibility Testing 🔍
- Conducted extensive testing on multiple browsers (Chrome, Firefox, Safari, Edge).
- Fixed UI inconsistencies and responsiveness issues.
- Ensured accessibility compliance with WCAG standards.

Beta Testing Begins 📢
- Launched beta version for a select group of users.
- Gathered feedback on UI/UX, performance, and usability.
- Identified and resolved reported bugs and performance bottlenecks.

Bug Fixing & Security Enhancements 🛡️
- Addressed reported bugs and refined UI elements.
- Strengthened authentication mechanisms and encryption protocols.
- Conducted penetration testing and security audits.

CI/CD Pipeline Implementation 🔄
- Automated deployment process using CI/CD pipelines.
- Improved version control with Git for better team collaboration.
- Streamlined rollback strategies for error recovery.

Final UI/UX Enhancements 🎨
- Refined UI based on beta testing feedback.
- Improved mobile responsiveness for a seamless user experience.
- Conducted usability testing to ensure a smooth workflow.
Final Testing & Deployment Readiness ✅
- Conducted full-scale integration testing.
- Verified system scalability and load performance.
- Prepared detailed documentation for future development and maintenance.

Official Public Launch 🎉
- Successfully launched the fully optimized and redesigned application.
- Initiated a marketing push to onboard new users.
- Provided ongoing monitoring for stability and user adoption
Post-Launch Enhancements & Scaling 
- Monitored analytics to assess user engagement.
- Collected post-launch feedback for iterative improvements.
- Planned next-phase features for future scalability and integration.